Modélisation des menaces#
Avertissement
Ce chapitre est conceptuel et pédagogique. Tous les exemples d’attaque présentés sont fictifs et construits à des fins d’illustration. Aucun système réel n’est ciblé. La modélisation des menaces est une activité défensive : elle vise à anticiper les risques pour mieux les contenir.
La modélisation des menaces (threat modeling) est l’activité qui consiste à identifier, classer et prioriser les risques de sécurité d’un système avant qu’ils ne se concrétisent. Contrairement aux tests d’intrusion (qui évaluent ce qui existe), la modélisation des menaces intervient en amont — idéalement dès la conception — pour orienter les choix d’architecture.
Les prérequis de ce chapitre sont : une familiarité avec les architectures microservices, les protocoles HTTP/TLS, et les bases STRIDE abordées dans architecture/20_securite_conception.md.
STRIDE appliqué aux microservices#
STRIDE est un acronyme mnémotechnique créé par Microsoft pour catégoriser les menaces sur un système. Chaque lettre correspond à une propriété de sécurité violée :
Lettre |
Menace |
Propriété violée |
|---|---|---|
S |
Spoofing (usurpation d’identité) |
Authenticité |
T |
Tampering (altération) |
Intégrité |
R |
Repudiation (répudiation) |
Non-répudiation |
I |
Information Disclosure (divulgation) |
Confidentialité |
D |
Denial of Service (déni de service) |
Disponibilité |
E |
Elevation of Privilege (élévation de privilèges) |
Autorisation |
Application à un système microservices concret#
Considérons une plateforme e-commerce composée de :
Un API Gateway exposé sur Internet (entrée unique)
Un service Auth (JWT, OAuth 2.0)
Un service Orders (commandes, base PostgreSQL)
Un service Payments (intégration PSP externe)
Un bus de messages Kafka interne
Un service Notifications (email/SMS)
Pour chaque composant, on applique STRIDE systématiquement :
API Gateway
Spoofing : un attaquant forge un en-tête
X-User-Idsi le gateway ne valide pas les tokens en amont.Denial of Service : flood HTTP, slowloris, amplification.
Information Disclosure : stack traces exposées dans les réponses d’erreur.
Service Auth
Spoofing : clé de signature JWT faible ou exposée → forge de tokens valides.
Elevation of Privilege : injection dans le champ
roledu payload JWT si la validation est absente.Repudiation : absence de logs d’authentification → impossibilité d’auditer les connexions.
Kafka (bus interne)
Tampering : un service compromis publie des messages falsifiés sans signature de message.
Information Disclosure : topics non chiffrés contenant des données personnelles.
Spoofing : absence d’authentification mTLS entre producteurs et courtiers.
Service Payments
Tampering : modification du montant entre le service Orders et le service Payments si l’intégrité du message n’est pas vérifiée (HMAC manquant).
Information Disclosure : numéros de carte stockés en clair dans les logs.
DFD — Diagramme de flux de données
STRIDE s’applique sur les éléments d’un DFD (Data Flow Diagram) : processus, flux de données, entités externes et zones de confiance (trust boundaries). L’outil pytm (Python Threat Modeling) permet de générer des DFD et d’automatiser l’application de STRIDE.
Arbres d’attaque#
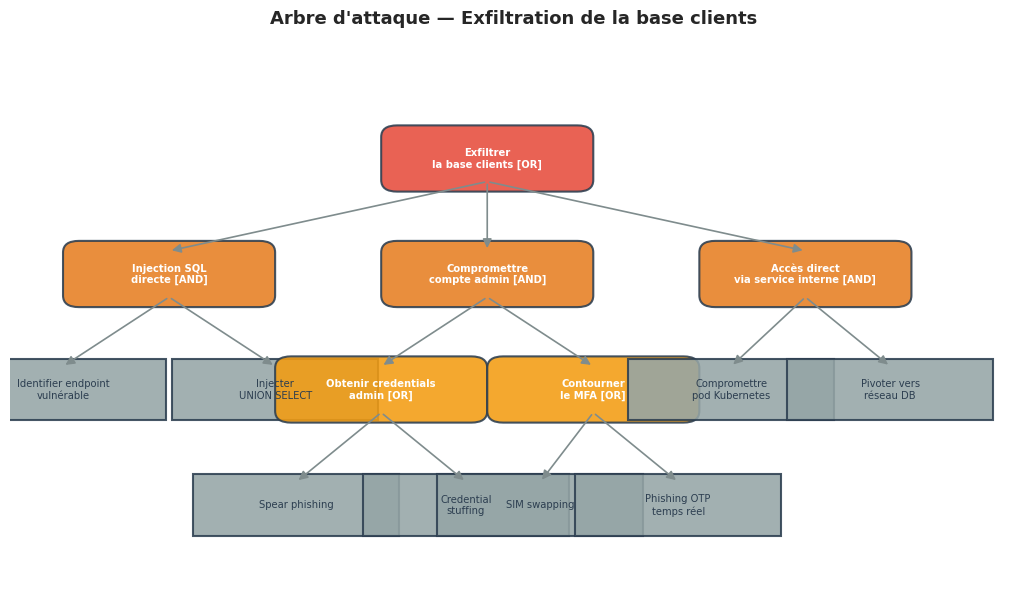
Un arbre d’attaque formalise les chemins qu’un attaquant peut emprunter pour atteindre un objectif. La racine est l’objectif de l’attaquant ; les nœuds internes décomposent cet objectif en sous-objectifs ; les feuilles représentent des actions atomiques.
Nœuds AND / OR#
Nœud OR : l’attaquant réussit si au moins un fils est réalisé. Il choisira le chemin de moindre résistance.
Nœud AND : l’attaquant doit réaliser tous les fils. Le coût total est la somme des coûts fils.
Coût d’attaque#
Chaque feuille peut être annotée par :
Coût (temps, argent, compétence requise)
Probabilité de succès
Détectabilité
Ces métriques permettent de prioriser les contre-mesures : on traite en priorité les feuilles peu coûteuses et peu détectables.
Exemple : arbre d’attaque contre une API web#
Objectif racine : Exfiltrer la base clients
[OR] Exfiltrer la base clients
├── [AND] Injection SQL directe
│ ├── Identifier un endpoint vulnérable (fuzzing)
│ └── Injecter une requête UNION SELECT
├── [AND] Compromission d'un compte admin
│ ├── [OR] Obtenir les credentials admin
│ │ ├── Phishing ciblé (spear phishing)
│ │ └── Credential stuffing (liste de fuites)
│ └── Contourner le MFA
│ ├── SIM swapping (téléphonie)
│ └── Phishing OTP en temps réel
└── [AND] Accès direct à la base via un service interne
├── Compromettre un pod Kubernetes interne
└── Pivoter vers le réseau de la base de données
La cellule suivante visualise cet arbre avec NetworkX.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
G = nx.DiGraph()
nodes = {
"root": ("Exfiltrer\nla base clients", "OR", "#e74c3c"),
"sqli": ("Injection SQL\ndirecte", "AND", "#e67e22"),
"sqli1": ("Identifier endpoint\nvulnérable", "leaf", "#95a5a6"),
"sqli2": ("Injecter\nUNION SELECT", "leaf", "#95a5a6"),
"admin": ("Compromettre\ncompte admin", "AND", "#e67e22"),
"creds": ("Obtenir credentials\nadmin", "OR", "#f39c12"),
"creds1": ("Spear phishing", "leaf", "#95a5a6"),
"creds2": ("Credential\nstuffing", "leaf", "#95a5a6"),
"mfa": ("Contourner\nle MFA", "OR", "#f39c12"),
"mfa1": ("SIM swapping", "leaf", "#95a5a6"),
"mfa2": ("Phishing OTP\ntemps réel", "leaf", "#95a5a6"),
"pivot": ("Accès direct\nvia service interne","AND","#e67e22"),
"pivot1": ("Compromettre\npod Kubernetes", "leaf", "#95a5a6"),
"pivot2": ("Pivoter vers\nréseau DB", "leaf", "#95a5a6"),
}
edges = [
("root", "sqli"), ("root", "admin"), ("root", "pivot"),
("sqli", "sqli1"), ("sqli", "sqli2"),
("admin", "creds"), ("admin", "mfa"),
("creds", "creds1"), ("creds", "creds2"),
("mfa", "mfa1"), ("mfa", "mfa2"),
("pivot", "pivot1"), ("pivot", "pivot2"),
]
G.add_nodes_from(nodes.keys())
G.add_edges_from(edges)
pos = {
"root": (4, 6),
"sqli": (1, 4.5), "admin": (4, 4.5), "pivot": (7, 4.5),
"sqli1": (0, 3), "sqli2": (2, 3),
"creds": (3, 3), "mfa": (5, 3),
"creds1": (2.2, 1.5),"creds2":(3.8, 1.5),
"mfa1": (4.5, 1.5),"mfa2": (5.8, 1.5),
"pivot1": (6.3, 3), "pivot2": (7.8, 3),
}
fig, ax = plt.subplots(figsize=(13, 7))
ax.set_xlim(-0.5, 9)
ax.set_ylim(0.5, 7.5)
ax.axis("off")
ax.set_title("Arbre d'attaque — Exfiltration de la base clients", fontsize=13, fontweight="bold", pad=14)
for edge in edges:
x0, y0 = pos[edge[0]]
x1, y1 = pos[edge[1]]
ax.annotate("", xy=(x1, y1 + 0.3), xytext=(x0, y0 - 0.3),
arrowprops=dict(arrowstyle="-|>", color="#7f8c8d", lw=1.2))
for nid, (label, ntype, color) in nodes.items():
x, y = pos[nid]
shape = "round,pad=0.15" if ntype != "leaf" else "square,pad=0.12"
bbox = FancyBboxPatch((x - 0.85, y - 0.28), 1.7, 0.56,
boxstyle=shape, linewidth=1.5,
edgecolor="#2c3e50", facecolor=color, alpha=0.88)
ax.add_patch(bbox)
tag = {"OR": " [OR]", "AND": " [AND]", "leaf": ""}.get(ntype, "")
ax.text(x, y, label + tag, ha="center", va="center",
fontsize=7.2, color="white" if ntype != "leaf" else "#2c3e50",
fontweight="bold" if ntype != "leaf" else "normal")
plt.savefig("attack_tree.png", dpi=120, bbox_inches="tight")
plt.show()
MITRE ATT&CK#
MITRE ATT&CK (Adversarial Tactics, Techniques, and Common Knowledge) est une base de connaissances ouverte qui catalogue les tactiques et techniques utilisées par des acteurs malveillants réels. Elle est organisée en matrices selon le domaine d’application : Enterprise, Mobile, ICS.
Structure de la matrice Enterprise#
La matrice Enterprise compte 14 tactiques ordonnées chronologiquement selon la progression d’une attaque :
Reconnaissance
Resource Development
Initial Access
Execution
Persistence
Privilege Escalation
Defense Evasion
Credential Access
Discovery
Lateral Movement
Collection
Command and Control
Exfiltration
Impact
Chaque tactique regroupe des techniques (ex. T1190 — Exploit Public-Facing Application) qui peuvent avoir des sous-techniques (ex. T1190.001).
Mapping sur un scénario : compromission d’une API web#
Voici comment mapper une attaque fictive sur ATT&CK :
Phase |
Tactique |
Technique |
ID |
|---|---|---|---|
1 |
Reconnaissance |
Active Scanning — Vulnerability Scanning |
T1595.002 |
2 |
Initial Access |
Exploit Public-Facing Application |
T1190 |
3 |
Execution |
Command and Scripting Interpreter |
T1059 |
4 |
Persistence |
Web Shell |
T1505.003 |
5 |
Credential Access |
OS Credential Dumping |
T1003 |
6 |
Lateral Movement |
Remote Services — SSH |
T1021.004 |
7 |
Collection |
Data from Local System |
T1005 |
8 |
Exfiltration |
Exfiltration Over Web Service |
T1567 |
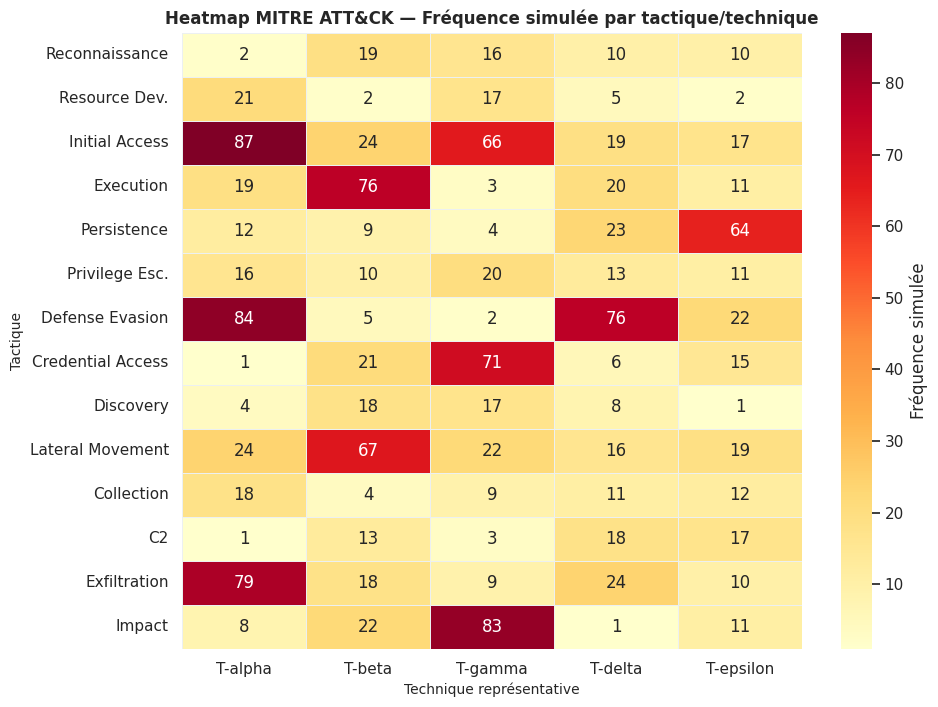
La cellule suivante simule une heatmap de fréquence des techniques par tactique.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.0)
tactics = [
"Reconnaissance", "Resource Dev.", "Initial Access", "Execution",
"Persistence", "Privilege Esc.", "Defense Evasion", "Credential Access",
"Discovery", "Lateral Movement", "Collection", "C2",
"Exfiltration", "Impact"
]
techniques = [
"T-alpha", "T-beta", "T-gamma", "T-delta", "T-epsilon"
]
rng = np.random.default_rng(42)
freq = rng.integers(0, 25, size=(len(tactics), len(techniques))).astype(float)
# Renforcer quelques cases pour illustrer un scénario réaliste
hot = [(2, 0), (2, 2), (3, 1), (4, 4), (6, 0), (6, 3), (7, 2), (9, 1), (12, 0), (13, 2)]
for r, c in hot:
freq[r, c] = rng.integers(60, 95)
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(
freq,
xticklabels=techniques,
yticklabels=tactics,
annot=True, fmt=".0f",
cmap="YlOrRd",
linewidths=0.4,
linecolor="#ecf0f1",
cbar_kws={"label": "Fréquence simulée"},
ax=ax
)
ax.set_title("Heatmap MITRE ATT&CK — Fréquence simulée par tactique/technique", fontsize=12, fontweight="bold")
ax.set_xlabel("Technique représentative", fontsize=10)
ax.set_ylabel("Tactique", fontsize=10)
ax.tick_params(axis="x", rotation=0)
ax.tick_params(axis="y", rotation=0)
plt.savefig("mitre_heatmap.png", dpi=120, bbox_inches="tight")
plt.show()
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.0)
tactics_clean = [
"Reconnaissance", "Resource Dev.", "Initial Access", "Execution",
"Persistence", "Privilege Esc.", "Defense Evasion", "Credential Access",
"Discovery", "Lateral Movement", "Collection", "C2",
"Exfiltration", "Impact"
]
techniques_clean = ["T-alpha", "T-beta", "T-gamma", "T-delta", "T-epsilon"]
rng = np.random.default_rng(42)
freq = rng.integers(0, 25, size=(len(tactics_clean), len(techniques_clean))).astype(float)
hot = [(2, 0), (2, 2), (3, 1), (4, 4), (6, 0), (6, 3), (7, 2), (9, 1), (12, 0), (13, 2)]
for r, c in hot:
freq[r, c] = rng.integers(60, 95)
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(
freq,
xticklabels=techniques_clean,
yticklabels=tactics_clean,
annot=True, fmt=".0f",
cmap="YlOrRd",
linewidths=0.4,
linecolor="#ecf0f1",
cbar_kws={"label": "Fréquence simulée"},
ax=ax
)
ax.set_title("Heatmap MITRE ATT&CK — Fréquence simulée par tactique/technique", fontsize=12, fontweight="bold")
ax.set_xlabel("Technique représentative", fontsize=10)
ax.set_ylabel("Tactique", fontsize=10)
ax.tick_params(axis="x", rotation=0)
ax.tick_params(axis="y", rotation=0)
plt.savefig("mitre_heatmap.png", dpi=120, bbox_inches="tight")
plt.show()
Extrait JSON STIX (format d’échange ATT&CK)#
{
"type": "attack-pattern",
"spec_version": "2.1",
"id": "attack-pattern--3f886f2a-13fc-4027-81c5-6b2cc7f2a0fc",
"name": "Exploit Public-Facing Application",
"external_references": [
{
"source_name": "mitre-attack",
"external_id": "T1190",
"url": "https://attack.mitre.org/techniques/T1190"
}
],
"kill_chain_phases": [
{
"kill_chain_name": "mitre-attack",
"phase_name": "initial-access"
}
],
"x_mitre_platforms": ["Linux", "Windows", "macOS", "Network"],
"x_mitre_data_sources": ["Application Log: Application Log Content"]
}
DREAD et CVSS v3.1#
DREAD#
DREAD est un modèle de scoring qualitatif (anciennement utilisé chez Microsoft) composé de 5 critères, chacun noté de 1 à 10 :
Critère |
Signification |
|---|---|
Damage |
Impact si l’attaque réussit |
Reproducibility |
Facilité à reproduire l’attaque |
Exploitability |
Compétence requise pour exploiter |
Affected users |
Proportion d’utilisateurs impactés |
Discoverability |
Facilité à découvrir la vulnérabilité |
Score DREAD = moyenne des 5 critères. Simple mais subjectif — CVSS lui est préféré pour la rigueur.
CVSS v3.1#
Le Common Vulnerability Scoring System v3.1 fournit un score objectif sur 10 à partir de vecteurs formalisés.
Métriques de base (Base Score) :
Vecteur |
Valeurs |
Signification |
|---|---|---|
AV (Attack Vector) |
N/A/L/P |
Network, Adjacent, Local, Physical |
AC (Attack Complexity) |
L/H |
Low, High |
PR (Privileges Required) |
N/L/H |
None, Low, High |
UI (User Interaction) |
N/R |
None, Required |
S (Scope) |
U/C |
Unchanged, Changed |
C (Confidentiality) |
N/L/H |
None, Low, High |
I (Integrity) |
N/L/H |
None, Low, High |
A (Availability) |
N/L/H |
None, Low, High |
Le vecteur CVSS s’écrit : CVSS:3.1/AV:N/AC:L/PR:N/UI:N/S:C/C:H/I:H/A:H → Score 10.0 (critique).
Métriques temporelles (Temporal) : exploitabilité, niveau de remédiation, confiance dans le rapport.
Métriques d’environnement (Environmental) : ajustement selon le contexte opérationnel.
sns.set_theme(style="whitegrid", palette="muted", font_scale=1.1)
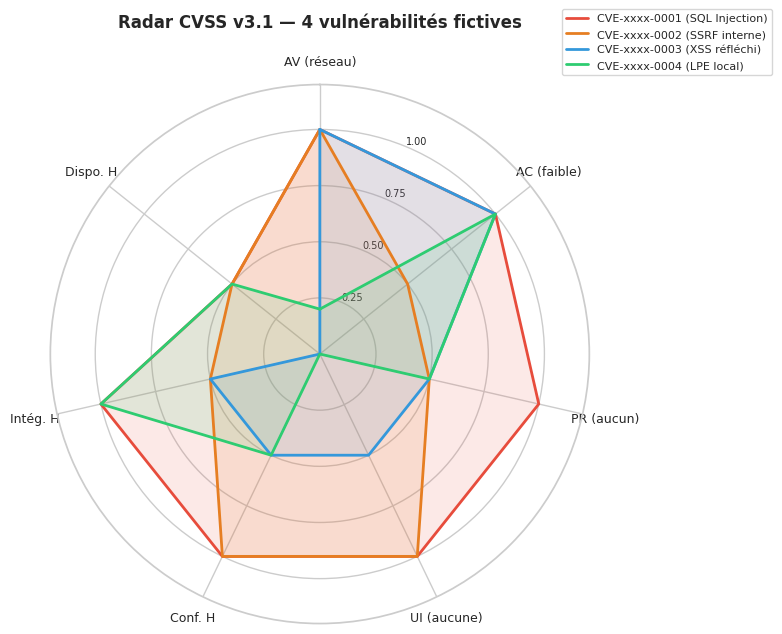
# Simulation CVSS v3.1 radar — 4 vulnérabilités fictives
categories = ["AV (réseau)", "AC (faible)", "PR (aucun)", "UI (aucune)", "Conf. H", "Intég. H", "Dispo. H"]
N = len(categories)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
angles += angles[:1]
vulns = {
"CVE-xxxx-0001\n(SQL Injection)": [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.5],
"CVE-xxxx-0002\n(SSRF interne)": [1.0, 0.5, 0.5, 1.0, 1.0, 0.5, 0.5],
"CVE-xxxx-0003\n(XSS réfléchi)": [1.0, 1.0, 0.5, 0.5, 0.5, 0.5, 0.0],
"CVE-xxxx-0004\n(LPE local)": [0.2, 1.0, 0.5, 0.0, 0.5, 1.0, 0.5],
}
colors = ["#e74c3c", "#e67e22", "#3498db", "#2ecc71"]
fig, ax = plt.subplots(figsize=(7, 7), subplot_kw=dict(polar=True))
ax.set_theta_offset(np.pi / 2)
ax.set_theta_direction(-1)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=9)
ax.set_ylim(0, 1.2)
ax.set_yticks([0.25, 0.5, 0.75, 1.0])
ax.set_yticklabels(["0.25", "0.50", "0.75", "1.00"], fontsize=7)
ax.set_title("Radar CVSS v3.1 — 4 vulnérabilités fictives", fontsize=12, fontweight="bold", pad=20)
for (label, values), color in zip(vulns.items(), colors):
vals = values + values[:1]
ax.plot(angles, vals, color=color, linewidth=2, label=label.replace("\n", " "))
ax.fill(angles, vals, alpha=0.12, color=color)
ax.legend(loc="upper right", bbox_to_anchor=(1.35, 1.15), fontsize=8)
plt.savefig("cvss_radar.png", dpi=120, bbox_inches="tight")
plt.show()
PASTA — Process for Attack Simulation and Threat Analysis#
PASTA est une méthodologie de threat modeling orientée risque en 7 étapes, qui aligne la vision technique et la vision métier.
Étape 1 — Définir les objectifs métier et de sécurité Exemple : « Protéger les données de paiement des clients, garantir la disponibilité du tunnel de commande. »
Étape 2 — Définir la portée technique Inventaire des composants, flux de données, technologies. On produit un DFD de niveau 0.
Étape 3 — Décomposer l’application DFD détaillé (niveaux 1 et 2), identification des zones de confiance, des points d’entrée.
Étape 4 — Analyser les menaces On consulte les bases (CVE, MITRE ATT&CK, NVD) pour identifier les menaces applicables à chaque composant.
Étape 5 — Identifier les vulnérabilités On mappe les menaces sur les vulnérabilités existantes via des scans (SAST, DAST, SCA). Cette étape produit une liste hiérarchisée.
Étape 6 — Modéliser les attaques (arbres d’attaque) Pour chaque vulnérabilité critique, on construit un arbre d’attaque comme présenté en section 2.
Étape 7 — Analyser le risque résiduel et définir les contre-mesures On calcule le risque = probabilité × impact, on identifie les contrôles existants, on quantifie le risque résiduel et on priorise les actions correctives.
PASTA vs STRIDE
STRIDE est orienté composants (on parcourt les éléments du DFD). PASTA est orientée risque métier (on part des objectifs business et on descend vers le technique). Dans la pratique, les deux approches se complètent : STRIDE pour énumérer exhaustivement les menaces par composant, PASTA pour prioriser en fonction du contexte métier.
Threat modeling en pratique#
Quand modéliser les menaces ?#
La modélisation des menaces est la plus efficace (et la moins coûteuse) lorsqu’elle est réalisée :
Lors de la conception d’une nouvelle fonctionnalité ou d’un nouveau service
Lors de changements architecturaux significatifs (ajout d’un composant, changement de modèle d’authentification)
Lors de la migration vers un nouveau provider cloud ou un nouveau paradigme (microservices, serverless)
Périodiquement (revue annuelle ou après un incident de sécurité)
Qui implique-t-on ?#
Un threat model réussi réunit des perspectives complémentaires :
Rôle |
Apport |
|---|---|
Architecte |
Vue d’ensemble du système, contraintes techniques |
Développeur |
Détails d’implémentation, connaissance du code |
Ops / SRE |
Connaissance de l’infrastructure, surface d’attaque réseau |
Security Engineer |
Connaissance des techniques d’attaque, MITRE ATT&CK |
Product Owner |
Contexte métier, criticité des données |
Artefacts produits#
À l’issue d’une session de threat modeling, on documente :
Le DFD annoté avec les zones de confiance
La liste STRIDE : pour chaque composant, les menaces applicables
Les arbres d’attaque pour les scénarios critiques
La liste des contrôles : contrôles existants et contrôles recommandés
Le registre de risques : risque brut, contrôles, risque résiduel, propriétaire, date de revue
Exemple de threat model YAML#
threat_model:
system: "API e-commerce"
date: "2026-03-01"
version: "1.0"
components:
- name: api_gateway
type: process
trust_boundary: internet_edge
threats:
- id: T-001
category: STRIDE-D
description: "Flood HTTP saturant les workers WSGI"
likelihood: high
impact: high
controls:
existing: ["rate limiting nginx (100 req/s)"]
recommended: ["WAF avec règles DDoS L7", "Circuit breaker Envoy"]
risk_score: 8.5
owner: infra_team
review_date: "2026-09-01"
- id: T-002
category: STRIDE-S
description: "Forge d'en-tête X-User-Id si JWT non validé"
likelihood: medium
impact: critical
controls:
existing: []
recommended: ["Valider signature JWT dans le gateway", "Supprimer X-User-Id des requêtes entrantes"]
risk_score: 9.0
owner: dev_team
review_date: "2026-04-15"
Outils de threat modeling
OWASP Threat Dragon : outil open-source avec interface graphique pour dessiner des DFD et annoter les menaces STRIDE.
pytm : bibliothèque Python qui génère des DFD, applique STRIDE et produit des rapports HTML.
Microsoft Threat Modeling Tool : outil desktop avec des templates pour Azure.
IriusRisk / ThreatModeler : plateformes commerciales intégrées aux pipelines CI/CD.
Résumé#
STRIDE structure l’analyse des menaces en 6 catégories liées aux propriétés de sécurité fondamentales ; il s’applique composant par composant sur un DFD annoté avec les zones de confiance.
Les arbres d’attaque modélisent les chemins d’attaque sous forme hiérarchique AND/OR ; l’annotation par coût et probabilité permet de prioriser les contre-mesures.
MITRE ATT&CK est la référence industrielle pour mapper les comportements adversariaux réels sur 14 tactiques et des centaines de techniques, avec un format d’échange STIX/JSON interopérable.
CVSS v3.1 fournit un score objectif sur 10 basé sur des vecteurs formalisés (AV, AC, PR, UI, S, C, I, A) ; les métriques temporelles et environnementales permettent d’adapter le score au contexte.
DREAD est un modèle qualitatif plus simple, utile pour des évaluations rapides, mais moins rigoureux que CVSS et peu adapté aux comparaisons inter-organisations.
PASTA aligne la modélisation des menaces sur les objectifs métier en 7 étapes, depuis les objectifs business jusqu’aux arbres d’attaque et à l’analyse du risque résiduel.
STRIDE et PASTA se complètent : STRIDE pour l’exhaustivité par composant, PASTA pour la priorisation métier.
La modélisation des menaces est un artefact vivant : elle doit être mise à jour lors de changements architecturaux et revue périodiquement, idéalement intégrée dans le pipeline CI/CD (pytm, IriusRisk).
Les artefacts produits (DFD annoté, liste STRIDE, arbres d’attaque, registre de risques) constituent la documentation de sécurité de référence pour l’équipe et les auditeurs externes.
L’approche shift-left impose de réaliser la modélisation des menaces en phase de conception, avant que le code soit écrit, pour minimiser le coût des corrections.