Expressions régulières avancées#
Les expressions régulières (regular expressions, ou regex) constituent l’un des langages les plus puissants et les plus universels de l’informatique. Elles permettent de décrire des motifs de texte avec une précision et une concision remarquables : reconnaître une adresse IP, extraire un horodatage, valider un email, reformater une date. Maîtriser les expressions régulières dans l’environnement Unix, c’est maîtriser un outil qui traverse tous les outils — grep, sed, awk, vim, less, et la quasi-totalité des langages de programmation. Ce chapitre présente les trois familles de regex disponibles sous Linux et leurs spécificités pratiques.
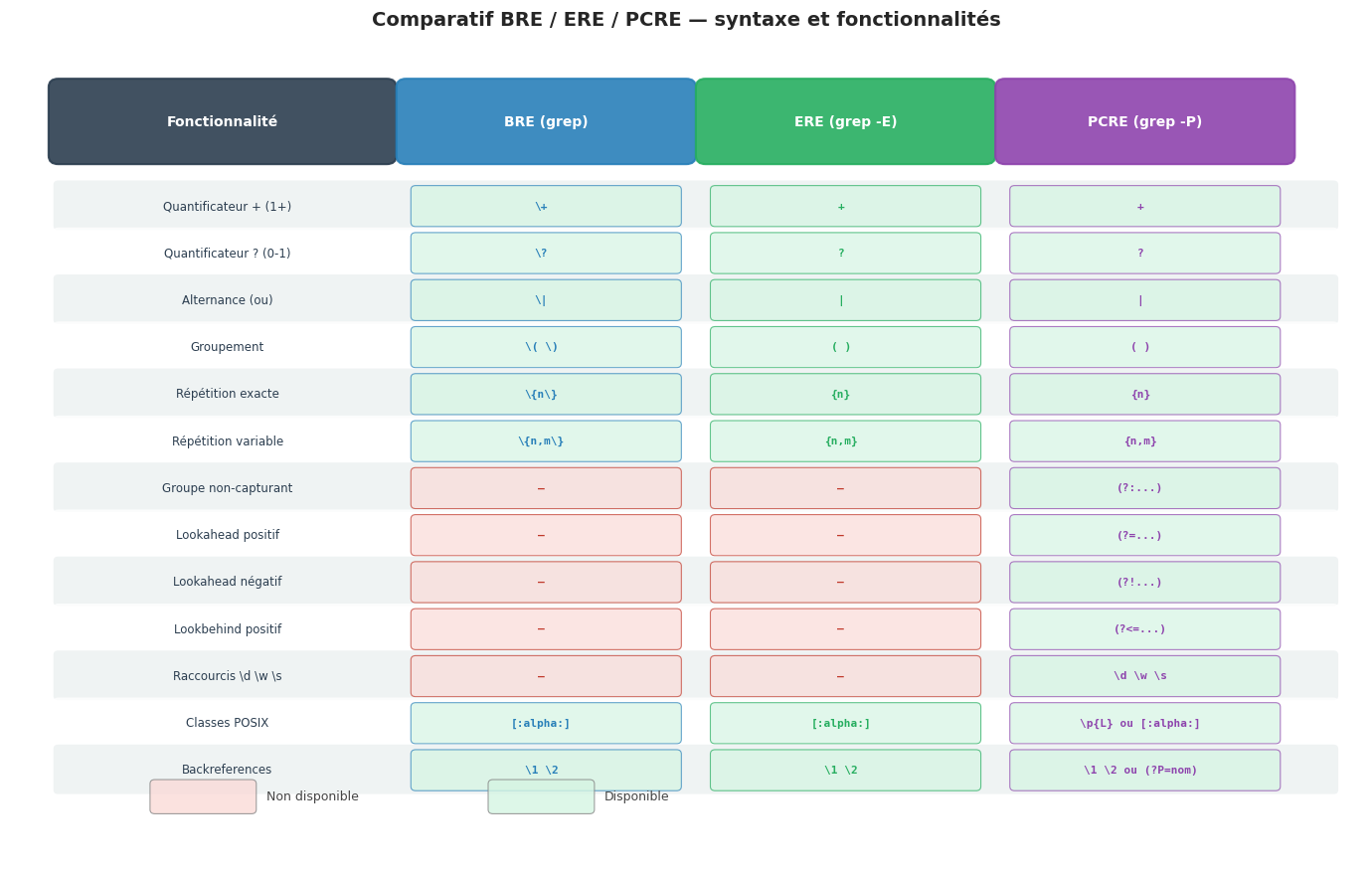
BRE, ERE et PCRE : trois familles de regex#
L’écosystème Unix connaît trois grandes familles d’expressions régulières, chacune avec sa propre syntaxe et ses propres capacités.
Définition 56 (BRE — Basic Regular Expressions)
Les expressions régulières de base (BRE) sont définies par la norme POSIX et constituent le mode par défaut de grep et sed. En BRE, les métacaractères d’alternance |, de groupement (), de quantificateurs +, ? et {n,m} doivent être précédés d’un antislash pour être interprétés comme des opérateurs regex. Sans antislash, ils sont traités comme des caractères littéraux.
Définition 57 (ERE — Extended Regular Expressions)
Les expressions régulières étendues (ERE) sont également définies par POSIX et constituent une syntaxe plus naturelle : les métacaractères +, ?, |, () et {n,m} sont des opérateurs sans antislash. ERE est activé avec grep -E (ou egrep), sed -E (ou sed -r selon les systèmes) et est le mode par défaut de awk.
Définition 58 (PCRE — Perl-Compatible Regular Expressions)
Les expressions régulières compatibles Perl (PCRE) vont bien au-delà de la norme POSIX. Elles ajoutent les lookaheads, lookbehinds, les groupes non capturants (?:...), les références arrière nommées (?P<nom>...), les séquences \d, \w, \s et bien d’autres fonctionnalités. Sous Linux, PCRE est disponible via grep -P et la bibliothèque libpcre. Attention : PCRE n’est pas portable sur tous les systèmes Unix (macOS par exemple utilise BSD grep).
Remarque 46
Règle pratique pour choisir sa famille :
Utilisez BRE (mode par défaut) pour la compatibilité maximale dans les scripts portables.
Utilisez ERE (
grep -E,sed -E) dès que la syntaxe le permet, pour des expressions plus lisibles.Utilisez PCRE (
grep -P) uniquement lorsque vous avez besoin de lookaheads, lookbehinds ou de\d/\w/\s, et uniquement dans des environnements Linux contrôlés.Dans
awk, ERE est le mode natif : les regex se placent entre/slashes/.
Métacaractères ERE essentiels#
Voici les métacaractères ERE à maîtriser, avec leur signification et des exemples concrets.
Exemple 30 (Métacaractères ERE de base)
Métacaractère |
Signification |
Exemple |
Correspond à |
|---|---|---|---|
|
N’importe quel caractère (sauf |
|
|
|
0 ou plusieurs répétitions |
|
|
|
1 ou plusieurs répétitions |
|
|
|
0 ou 1 répétition (optionnel) |
|
|
|
Alternance (ou) |
|
|
|
Groupement |
|
|
|
Exactement n répétitions |
|
|
|
Entre n et m répétitions |
|
|
|
Au moins n répétitions |
|
|
|
Début de ligne |
|
lignes commençant par |
|
Fin de ligne |
|
lignes finissant par |
|
Classe de caractères |
|
une voyelle |
|
Négation de classe |
|
tout sauf un chiffre |
|
Frontière de mot (PCRE/ERE) |
|
|
Différences de syntaxe BRE vs ERE#
# BRE : les opérateurs + ? | () {n,m} nécessitent un antislash
grep '\(erreur\|avertissement\)' fichier.log # BRE
grep '\b[0-9]\{1,3\}\.[0-9]\{1,3\}' ip.txt # BRE
# ERE : syntaxe naturelle, plus lisible
grep -E '(erreur|avertissement)' fichier.log # ERE
grep -E '\b[0-9]{1,3}\.[0-9]{1,3}' ip.txt # ERE
Classes de caractères POSIX#
Les classes de caractères POSIX offrent une alternative portable aux ranges comme [a-z], dont le comportement peut varier selon la locale.
Définition 59 (Classes de caractères POSIX)
Les classes POSIX s’utilisent à l’intérieur d’une expression entre crochets [[:classe:]]. Elles sont définies par la locale du système et sont donc portables et sensibles à l’encodage. Les principales classes sont :
[:alpha:]— lettres (majuscules et minuscules, accents inclus selon la locale)[:digit:]— chiffres décimaux0-9[:alnum:]— lettres et chiffres[:space:]— caractères d’espacement (espace, tabulation, saut de ligne, etc.)[:blank:]— espace et tabulation uniquement[:upper:]— lettres majuscules[:lower:]— lettres minuscules[:punct:]— caractères de ponctuation[:print:]— caractères imprimables (y compris espace)[:graph:]— caractères imprimables (sans espace)[:xdigit:]— chiffres hexadécimaux[0-9A-Fa-f][:cntrl:]— caractères de contrôle
# Trouver les lignes contenant uniquement des lettres et des espaces
grep '^[[:alpha:][:space:]]*$' fichier.txt
# Supprimer les caractères non imprimables
sed 's/[^[:print:]]//g' fichier_binaire.txt
# Trouver les identifiants (lettres, chiffres, tiret bas)
grep -E '^[[:alnum:]_]+$' identifiants.txt
# Supprimer les espaces de début et de fin
sed 's/^[[:space:]]*//; s/[[:space:]]*$//' fichier.txt
Remarque 47
Préférer [[:digit:]] à [0-9] et [[:alpha:]] à [a-zA-Z] pour écrire des scripts portables. Sur certains systèmes avec une locale non-C, [a-z] peut inclure des lettres accentuées ou même des majuscules selon l’ordre de tri de la locale. Les classes POSIX ont un comportement prédictible quelle que soit la locale.
Groupes capturants et backreferences avec sed#
L’une des fonctionnalités les plus puissantes des regex est la possibilité de capturer une partie du texte correspondant et de la réutiliser dans le remplacement.
Définition 60 (Groupes capturants)
Un groupe capturant est délimité par des parenthèses. Le texte correspondant au groupe est mémorisé et peut être réutilisé par une backreference :
En BRE (
sedsans-E) : les groupes s’écrivent\(et\), et les backreferences\1,\2, …,\9.En ERE (
sed -E) : les groupes s’écrivent(et)(sans antislash), et les backreferences restent\1,\2, …,\9.
# Inverser prénom et nom séparés par une virgule
# Entrée : "Dupont, Marie"
# Sortie : "Marie Dupont"
echo "Dupont, Marie" | sed 's/\([^,]*\), \(.*\)/\2 \1/' # BRE
echo "Dupont, Marie" | sed -E 's/([^,]*), (.*)/\2 \1/' # ERE
# Reformater une date AAAA-MM-JJ en JJ/MM/AAAA
echo "2024-03-15" | sed -E 's/([0-9]{4})-([0-9]{2})-([0-9]{2})/\3\/\2\/\1/'
# Doubler chaque mot (démo des backreferences)
echo "bonjour monde" | sed -E 's/([a-zA-Z]+)/\1 \1/g'
# Sortie : bonjour bonjour monde monde
# Entourer les nombres de crochets
echo "il y a 42 éléments et 7 groupes" | sed -E 's/[0-9]+/[&]/g'
# Le & désigne la totalité du motif correspondant
Références arrière dans la partie motif#
Les backreferences peuvent aussi apparaître dans la partie motif (pas seulement dans le remplacement), pour trouver des répétitions :
# Trouver les mots doublés (ex. "le le", "que que")
grep -E '\b([a-zA-ZÀ-ÿ]+) \1\b' texte.txt
# En BRE
grep '\b\([a-zA-ZÀ-ÿ]*\) \1\b' texte.txt
Lookahead et lookbehind avec grep -P#
Les assertions de position (lookahead et lookbehind) sont des extensions PCRE qui permettent de poser des conditions sur le contexte sans capturer ni consommer de caractères.
Définition 61 (Assertions de position PCRE)
(?=motif)— lookahead positif : la position doit être suivie demotif, sans le consommer.(?!motif)— lookahead négatif : la position ne doit pas être suivie demotif.(?<=motif)— lookbehind positif : la position doit être précédée demotif(de longueur fixe en PCRE).(?<!motif)— lookbehind négatif : la position ne doit pas être précédée demotif.
# Trouver les nombres suivis de " €" (mais ne pas inclure " €" dans le résultat)
echo "coûte 42 € et aussi 15 $ et 8 €" | grep -oP '[0-9]+(?= €)'
# Sortie :
# 42
# 8
# Trouver les mots précédés de "non-" sans inclure "non-"
echo "non-conformité, non-conformiste, conformité" | grep -oP '(?<=non-)\w+'
# Sortie :
# conformité
# conformiste
# Trouver les fichiers .log qui ne commencent pas par "debug_"
ls | grep -P '^(?!debug_).*\.log$'
# Extraire le contenu entre guillemets (sans inclure les guillemets)
echo 'message: "bonjour monde"' | grep -oP '(?<=")\w[\w\s]*(?=")'
Remarque 48
Les lookbehinds PCRE standard exigent que le motif du lookbehind ait une longueur fixe (ou un ensemble de longueurs fixes). (?<=ab|abc) est valide, mais (?<=[a-z]+) ne l’est pas dans la plupart des moteurs PCRE. Si vous avez besoin d’un lookbehind de longueur variable, Python (module re) ou perl offrent des alternatives.
sed -E : transformations pratiques#
sed avec l’option -E (ERE) est l’outil de choix pour les transformations de texte en flux. Voici un ensemble d’exemples pratiques.
```{prf:example} Transformations sed -E courantes
:label: example-17-02
```bash
# --- Nettoyage ---
# Supprimer les commentaires bash (# jusqu'à fin de ligne, hors guillemets)
sed -E 's/#[^"]*$//' script.sh
# Supprimer les lignes vides ou ne contenant que des espaces
sed -E '/^[[:space:]]*$/d' fichier.txt
# Normaliser les espaces multiples en un seul espace
sed -E 's/[[:space:]]+/ /g' fichier.txt
# --- Reformatage ---
# Convertir les URL http:// en https://
sed -E 's|http://([^/]+)|https://\1|g' urls.txt
# Extraire le domaine d'une URL
echo "https://www.exemple.fr/page/sous-page" \
| sed -E 's|https?://([^/]+).*|\1|'
# Formater un numéro de téléphone français (10 chiffres → XX XX XX XX XX)
echo "0612345678" | sed -E 's/([0-9]{2})([0-9]{2})([0-9]{2})([0-9]{2})([0-9]{2})/\1 \2 \3 \4 \5/'
# --- Extraction ---
# Extraire la valeur d'un champ clé=valeur
echo "utilisateur=alice timeout=30 retries=3" \
| sed -E 's/.*timeout=([0-9]+).*/\1/'
# Convertir un CSV en liste verticale (première colonne uniquement)
sed -E 's/^([^,]+),.*/\1/' donnees.csv
L’adressage dans sed#
sed peut appliquer des commandes à des plages de lignes ou à des lignes correspondant à un motif :
# Supprimer les lignes 5 à 10
sed '5,10d' fichier.txt
# Appliquer une substitution uniquement aux lignes contenant "TODO"
sed '/TODO/s/ancien/nouveau/g' fichier.txt
# Appliquer une substitution entre deux marqueurs
sed '/DEBUT/,/FIN/s/foo/bar/g' fichier.txt
# Supprimer tout entre deux marqueurs (inclus)
sed '/DEBUT/,/FIN/d' fichier.txt
# Insérer une ligne après chaque ligne correspondant au motif
sed -E '/^## /a\<!-- section -->' document.md
awk avec les regex#
awk intègre les expressions régulières de façon native, à la fois pour filtrer les lignes et pour manipuler les champs.
```{prf:definition} Regex dans awk
:label: definition-17-07
Dans awk, les regex s’utilisent de plusieurs façons :
/motif/ { action }— exécuteractionsur les lignes correspondant au motif.!/motif/ { action }— exécuteractionsur les lignes ne correspondant pas au motif.champ ~ /motif/— le champ correspond au motif (opérateur de correspondance~).champ !~ /motif/— le champ ne correspond pas au motif.match(chaine, /motif/)— tester si une chaîne contient le motif, avec accès àRSTARTetRLENGTH.
```bash
# Afficher les lignes dont le premier champ est un nombre
awk '$1 ~ /^[0-9]+$/ { print }' donnees.txt
# Afficher les lignes dont le troisième champ est une adresse email
awk '$3 ~ /^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$/ { print $1, $3 }' users.txt
# Ignorer les lignes vides et les commentaires
awk '!/^[[:space:]]*(#|$)/' config.ini
# Extraire la valeur d'une clé dans un fichier key=value
awk -F= '/^timeout/ { print $2 }' config.ini
# Calculer la somme des valeurs du champ 2, uniquement pour les lignes "actif"
awk '/actif/ { total += $2 } END { print "Total :", total }' rapport.txt
# Substitution avec sub() et gsub()
awk '{ gsub(/http:\/\//, "https://"); print }' urls.txt
Champs et séparateurs#
# Utiliser une regex comme séparateur de champs
awk -F '[;,|]' '{ print $1, $3 }' donnees.csv
# Séparateur de sortie différent du séparateur d'entrée
awk 'BEGIN { FS=","; OFS="|" } { $1=$1; print }' donnees.csv
Cas pratiques : extraire des données structurées#
Extraire des adresses IP#
# Extraire toutes les adresses IPv4 d'un fichier
grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}' acces.log
# Version plus stricte (0-255 par octet) avec PCRE
grep -oP '\b((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\b' acces.log
# Extraire les IPs uniques par ordre de fréquence décroissante
grep -oE '([0-9]{1,3}\.){3}[0-9]{1,3}' acces.log \
| sort | uniq -c | sort -rn | head -20
Extraire des dates#
# Extraire les dates au format JJ/MM/AAAA
grep -oE '[0-9]{2}/[0-9]{2}/[0-9]{4}' journal.txt
# Extraire les horodatages ISO 8601 (AAAA-MM-JJTHH:MM:SS)
grep -oP '[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}:[0-9]{2}' logs.txt
# Convertir les dates US (MM/DD/YYYY) en ISO (YYYY-MM-DD)
sed -E 's|([0-9]{2})/([0-9]{2})/([0-9]{4})|\3-\1-\2|g' dates_us.txt
Extraire des URLs#
# Extraire toutes les URLs d'un fichier HTML
grep -oE 'https?://[^"<> ]+' page.html
# Extraire uniquement les domaines
grep -oE 'https?://[^/"<> ]+' page.html | sed -E 's|https?://||'
# Extraire les URLs avec grep -P pour plus de précision
grep -oP 'https?://[^\s"<>]+' page.html
Valider et extraire des adresses email#
# Regex simple pour les emails (ne couvre pas tous les cas RFC 5321)
grep -oE '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' fichier.txt
# Extraire les emails et trier par domaine
grep -oE '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' fichier.txt \
| awk -F@ '{ print $2, $0 }' | sort -k1,1 | awk '{ print $2 }'
# Valider qu'une chaîne est un email (dans un script)
valider_email() {
local email="$1"
if echo "$email" | grep -qE '^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'; then
return 0
else
return 1
fi
}
Analyser des logs Apache/Nginx#
# Format de log Apache combiné :
# IP - - [date] "METHOD /path HTTP/1.1" code taille "referer" "user-agent"
# Extraire les codes HTTP 5xx (erreurs serveur)
grep -E '" [5][0-9]{2} ' acces.log
# Extraire les 10 pages les plus demandées (sans les ressources statiques)
awk '{ print $7 }' acces.log \
| grep -vE '\.(css|js|png|jpg|ico|woff)' \
| sort | uniq -c | sort -rn | head -10
# Extraire les IPs avec plus de 100 requêtes (potentiels bots)
awk '{ print $1 }' acces.log | sort | uniq -c | sort -rn | awk '$1 > 100'
# Calculer le volume total des transferts par code HTTP
awk '{ code=$9; taille=$10; if (taille ~ /^[0-9]+$/) total[code] += taille }
END { for (c in total) printf "HTTP %s : %.2f Mo\n", c, total[c]/1048576 }' acces.log
Résumé#
Ce chapitre a couvert les trois familles d’expressions régulières disponibles sous Linux et leur utilisation pratique :
BRE est le mode par défaut de
grepetsed: portable mais verbose, les opérateurs+,?,|,()et{n,m}nécessitent un antislash.ERE (
grep -E,sed -E,awk) offre une syntaxe plus naturelle et plus lisible, sans antislashes superflus.PCRE (
grep -P) ajoute les lookaheads, lookbehinds,\d/\w/\set les groupes nommés, au prix de la portabilité.Les classes POSIX (
[:alpha:],[:digit:], etc.) sont préférables aux ranges[a-z]pour la portabilité et la cohérence avec les locales.Les groupes capturants et backreferences (
\1,\2) permettent danssedde réarranger des parties du texte correspondant.awkintègre ERE nativement avec les opérateurs~et!~pour filtrer par champ.Des cas pratiques — extraction d’IPs, de dates, d’URLs, d’emails, analyse de logs — illustrent l’application concrète de ces techniques.
Dans le chapitre suivant, nous abordons la planification de tâches avec cron et les timers systemd, pour automatiser l’exécution périodique de scripts.