Structures de données natives#
Les listes (list)#
La liste est la structure de données la plus polyvalente de Python. C’est une séquence ordonnée, mutable et hétérogène : elle peut contenir des éléments de types différents, dans n’importe quel ordre, et son contenu peut être modifié après sa création. Sous le capot, Python implémente les listes comme des tableaux dynamiques (dynamic arrays) : une zone de mémoire contiguë qui se redimensionne automatiquement lorsque nécessaire.
# Création d'une liste
vide = []
nombres = [1, 2, 3, 4, 5]
hétérogène = [42, "bonjour", 3.14, True, None]
imbriquée = [[1, 2], [3, 4], [5, 6]] # Liste de listes
print(type(nombres))
print(len(nombres))
<class 'list'>
5
Indexation et slicing#
fruits = ["pomme", "banane", "cerise", "datte", "figue"]
# Accès par indice (négatifs depuis la fin)
print(fruits[0]) # Premier
print(fruits[-1]) # Dernier
print(fruits[-2]) # Avant-dernier
# Slicing : [début:fin:pas]
print(fruits[1:3]) # ["banane", "cerise"]
print(fruits[::-1]) # Inversion complète
print(fruits[::2]) # Un sur deux
# Modification par indice ou slice
fruits[0] = "abricot"
fruits[1:3] = ["citron", "mangue", "kiwi"] # Peut changer la longueur !
print(fruits)
pomme
figue
datte
['banane', 'cerise']
['figue', 'datte', 'cerise', 'banane', 'pomme']
['pomme', 'cerise', 'figue']
['abricot', 'citron', 'mangue', 'kiwi', 'datte', 'figue']
Méthodes essentielles#
ma_liste = [3, 1, 4, 1, 5, 9, 2, 6]
# Ajout
ma_liste.append(5) # Ajoute à la fin — O(1) amorti
ma_liste.insert(2, 99) # Insère à l'indice 2 — O(n)
ma_liste.extend([7, 8, 9]) # Ajoute tous les éléments — O(k)
print(ma_liste)
# Suppression
ma_liste.remove(99) # Supprime la première occurrence de 99 — O(n)
élément = ma_liste.pop() # Retire et retourne le dernier — O(1)
élément2 = ma_liste.pop(0) # Retire et retourne l'indice 0 — O(n)
print(f"Retiré en fin : {élément}, en début : {élément2}")
print(ma_liste)
[3, 1, 99, 4, 1, 5, 9, 2, 6, 5, 7, 8, 9]
Retiré en fin : 9, en début : 3
[1, 4, 1, 5, 9, 2, 6, 5, 7, 8]
# Tri
nombres = [5, 2, 8, 1, 9, 3]
nombres.sort() # Tri en place — O(n log n)
print(nombres)
nombres.sort(reverse=True) # Tri décroissant
print(nombres)
# sorted() retourne une nouvelle liste (n'affecte pas l'original)
original = [5, 2, 8, 1]
trié = sorted(original, key=lambda x: -x)
print(original) # Inchangé
print(trié)
# Autres méthodes
print([1, 2, 3].count(2)) # Nombre d'occurrences
print([1, 2, 3, 2].index(2)) # Indice de la première occurrence
[1, 2, 3, 5, 8, 9]
[9, 8, 5, 3, 2, 1]
[5, 2, 8, 1]
[8, 5, 2, 1]
1
1
Complexité des opérations#
Remarque 13
La complexité algorithmique des opérations sur les listes Python est déterminée par leur implémentation en tableau dynamique. Les opérations en fin de liste (append, pop()) sont en O(1) amorti. Les opérations en début ou au milieu (insert(0, …), pop(0), remove) nécessitent de décaler tous les éléments suivants et sont en O(n). Pour des insertions et suppressions fréquentes en tête de liste, la structure collections.deque est bien plus adaptée.
Listes imbriquées#
# Matrice 3×3
matrice = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
# Accès : matrice[ligne][colonne]
print(matrice[1][2]) # 6
# Transposée par compréhension
transposée = [[matrice[j][i] for j in range(3)] for i in range(3)]
for ligne in transposée:
print(ligne)
6
[1, 4, 7]
[2, 5, 8]
[3, 6, 9]
Les tuples (tuple)#
Le tuple est une séquence ordonnée et immuable. Une fois créé, son contenu ne peut plus être modifié. Cette immuabilité en fait un outil de choix pour représenter des données qui ne doivent pas changer : coordonnées géographiques, enregistrements de base de données, clés de dictionnaires composites.
# Création
vide = ()
singleton = (42,) # La virgule est obligatoire pour un singleton !
point = (3.0, 4.0)
coordonnées = (48.8566, 2.3522, "Paris")
# Le parenthèsage est optionnel (c'est la virgule qui fait le tuple)
triplet = 1, 2, 3
print(type(triplet))
# Immutabilité
try:
point[0] = 10
except TypeError as e:
print(f"TypeError : {e}")
<class 'tuple'>
TypeError : 'tuple' object does not support item assignment
Déballage (unpacking)#
# Déballage simple
x, y = (3.0, 4.0)
print(f"x = {x}, y = {y}")
# Échange de variables (pythonique, sans variable temporaire)
a, b = 10, 20
a, b = b, a
print(f"a = {a}, b = {b}")
# Déballage avec * (reste)
premier, *reste = [1, 2, 3, 4, 5]
print(f"premier = {premier}, reste = {reste}")
*début, dernier = [1, 2, 3, 4, 5]
print(f"début = {début}, dernier = {dernier}")
premier, *milieu, dernier = [1, 2, 3, 4, 5]
print(f"premier = {premier}, milieu = {milieu}, dernier = {dernier}")
x = 3.0, y = 4.0
a = 20, b = 10
premier = 1, reste = [2, 3, 4, 5]
début = [1, 2, 3, 4], dernier = 5
premier = 1, milieu = [2, 3, 4], dernier = 5
# Déballage dans une boucle
points = [(1, 2), (3, 4), (5, 6)]
for x, y in points:
print(f"Distance à l'origine : {(x**2 + y**2)**0.5:.3f}")
# Retourner plusieurs valeurs depuis une fonction
def divmod_perso(a, b):
return a // b, a % b # Retourne un tuple
quotient, reste = divmod_perso(17, 5)
print(f"17 ÷ 5 = {quotient} reste {reste}")
Distance à l'origine : 2.236
Distance à l'origine : 5.000
Distance à l'origine : 7.810
17 ÷ 5 = 3 reste 2
Tuples nommés (collections.namedtuple)#
from collections import namedtuple
# Définir un type enregistrement (comme une struct légère)
Point = namedtuple('Point', ['x', 'y'])
Étudiant = namedtuple('Étudiant', ['nom', 'note', 'filière'])
p = Point(3.0, 4.0)
print(p.x, p.y)
print(p[0], p[1]) # Aussi accessible par indice
print(f"Distance : {(p.x**2 + p.y**2)**0.5:.3f}")
alice = Étudiant("Alice", 18.5, "Informatique")
print(alice)
print(alice.nom)
# Les namedtuples sont immuables comme les tuples ordinaires
# Mais on peut créer une version modifiée avec _replace
alice_m1 = alice._replace(filière="Mathématiques")
print(alice_m1)
3.0 4.0
3.0 4.0
Distance : 5.000
Étudiant(nom='Alice', note=18.5, filière='Informatique')
Alice
Étudiant(nom='Alice', note=18.5, filière='Mathématiques')
Les dictionnaires (dict)#
Le dictionnaire est une structure de données clé-valeur qui repose sur une table de hachage (hash table). Il permet l’accès, l’insertion et la suppression d’éléments en O(1) en moyenne. Depuis Python 3.7, les dictionnaires préservent l’ordre d’insertion — une propriété garantie par la spécification du langage.
# Création
vide = {}
vide2 = dict()
scores = {"Alice": 95, "Bob": 87, "Charlie": 91}
from_tuples = dict([("a", 1), ("b", 2), ("c", 3)])
par_compréhension = {x: x**2 for x in range(5)}
print(scores)
print(par_compréhension)
{'Alice': 95, 'Bob': 87, 'Charlie': 91}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
Accès et modification#
scores = {"Alice": 95, "Bob": 87, "Charlie": 91}
# Accès direct (lève KeyError si la clé est absente)
print(scores["Alice"])
# Accès sécurisé avec get()
print(scores.get("Dave")) # None
print(scores.get("Dave", 0)) # 0 (valeur par défaut)
# Modification
scores["Alice"] = 98
scores["Dave"] = 79 # Insertion
del scores["Charlie"] # Suppression
print(scores)
# Test d'appartenance
print("Bob" in scores)
print("Charlie" in scores)
95
None
0
{'Alice': 98, 'Bob': 87, 'Dave': 79}
True
False
Itération sur un dictionnaire#
inventaire = {"pomme": 10, "banane": 5, "cerise": 25}
# Itérer sur les clés (comportement par défaut)
for clé in inventaire:
print(clé)
# Itérer sur les valeurs
for valeur in inventaire.values():
print(valeur)
# Itérer sur les paires clé-valeur
for clé, valeur in inventaire.items():
print(f"{clé}: {valeur}")
# Fusionner deux dictionnaires (Python 3.9+)
compléments = {"kiwi": 8, "mangue": 3}
total = inventaire | compléments
print(total)
pomme
banane
cerise
10
5
25
pomme: 10
banane: 5
cerise: 25
{'pomme': 10, 'banane': 5, 'cerise': 25, 'kiwi': 8, 'mangue': 3}
collections.defaultdict et collections.Counter#
from collections import defaultdict, Counter
# defaultdict : valeur par défaut automatique
groupes = defaultdict(list)
données = [("A", 1), ("B", 2), ("A", 3), ("B", 4), ("C", 5)]
for groupe, valeur in données:
groupes[groupe].append(valeur)
print(dict(groupes))
# Counter : comptage d'occurrences
texte = "abracadabra"
occurrences = Counter(texte)
print(occurrences)
print(occurrences.most_common(3))
mots = "le chat mange le chat noir et le chat".split()
fréquences = Counter(mots)
print(fréquences.most_common(3))
{'A': [1, 3], 'B': [2, 4], 'C': [5]}
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
[('a', 5), ('b', 2), ('r', 2)]
[('le', 3), ('chat', 3), ('mange', 1)]
Les ensembles (set et frozenset)#
Un ensemble est une collection non ordonnée d’éléments uniques. Comme le dictionnaire, il repose sur une table de hachage, ce qui garantit un test d’appartenance en O(1) — un avantage décisif sur les listes pour les grands jeux de données. Les éléments d’un ensemble doivent être hashables (immuables).
# Création
vide = set() # Attention : {} crée un dict vide, pas un set !
consonnes = {'b', 'c', 'd', 'f', 'g'}
depuis_liste = set([1, 2, 2, 3, 3, 3, 4]) # Élimine les doublons
print(depuis_liste)
# Test d'appartenance — O(1)
print('b' in consonnes)
print('a' in consonnes)
{1, 2, 3, 4}
True
False
Opérations ensemblistes#
A = {1, 2, 3, 4, 5}
B = {3, 4, 5, 6, 7}
# Union : éléments dans A ou B (ou les deux)
print(A | B)
print(A.union(B))
# Intersection : éléments dans A et B
print(A & B)
print(A.intersection(B))
# Différence : éléments dans A mais pas dans B
print(A - B)
print(A.difference(B))
# Différence symétrique : éléments dans l'un ou l'autre mais pas les deux
print(A ^ B)
print(A.symmetric_difference(B))
# Tests de sous-ensemble et sur-ensemble
print({1, 2} <= A) # Sous-ensemble
print(A >= {1, 2}) # Sur-ensemble
{1, 2, 3, 4, 5, 6, 7}
{1, 2, 3, 4, 5, 6, 7}
{3, 4, 5}
{3, 4, 5}
{1, 2}
{1, 2}
{1, 2, 6, 7}
{1, 2, 6, 7}
True
True
# Suppression des doublons en préservant l'ordre (astuce)
def dédupliquer_ordonné(séquence):
vu = set()
return [x for x in séquence if not (x in vu or vu.add(x))]
données = [3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5]
print(dédupliquer_ordonné(données))
[3, 1, 4, 5, 9, 2, 6]
frozenset : ensemble immuable#
# frozenset : hashable, peut servir de clé de dictionnaire
fs = frozenset({1, 2, 3})
print(type(fs))
# Usage : clé de dictionnaire (un set ordinaire ne peut pas)
graphe = {
frozenset({1, 2}): "arête A-B",
frozenset({2, 3}): "arête B-C",
}
print(graphe[frozenset({1, 2})])
<class 'frozenset'>
arête A-B
Choisir la bonne structure#
Choisir la bonne structure de données est souvent la décision la plus importante pour la performance et la lisibilité du code. Voici les critères principaux :
Définition 8 (Hashabilité)
Un objet est hashable si sa valeur de hachage ne change jamais au cours de sa vie (méthode __hash__) et s’il peut être comparé à d’autres objets (méthode __eq__). En pratique, les objets immuables sont hashables (int, float, str, tuple, frozenset), tandis que les objets mutables ne le sont pas (list, dict, set). La hashabilité est requise pour pouvoir utiliser un objet comme clé de dictionnaire ou comme élément d’un ensemble.
Critère |
|
|
|
|
|---|---|---|---|---|
Ordonné |
Oui |
Oui |
Oui (3.7+) |
Non |
Mutable |
Oui |
Non |
Oui |
Oui |
Doublons |
Oui |
Oui |
Clés non |
Non |
Hashable |
Non |
Si éléments hashables |
Non |
Non |
Accès par indice |
O(1) |
O(1) |
O(1) par clé |
Non |
Appartenance |
O(n) |
O(n) |
O(1) |
O(1) |
Exemple 2 (Choisir la structure adaptée)
Quelques règles pratiques pour guider le choix :
list: séquence dont l’ordre importe, avec possibilité de doublons, et qu’on modifie régulièrement. Idéale pour stocker des enregistrements dans un ordre précis.tuple: données structurées immuables (coordonnées, enregistrement de base de données), valeur de retour multiple d’une fonction, clé composite de dictionnaire.dict: association clé-valeur, accès rapide par clé, accumulation de données par catégorie. C’est la structure à préférer dès qu’on se retrouve à chercher un élément par un identifiant.set: élimination des doublons, tests d’appartenance fréquents, opérations ensemblistes. Remplace avantageusement une liste quand l’ordre n’importe pas et qu’on teste souventx in ....
collections et array#
Le module collections de la bibliothèque standard propose des structures de données spécialisées qui complètent les types natifs.
deque : file double d’accès#
from collections import deque
# deque (double-ended queue) : O(1) en tête ET en fin
file = deque([1, 2, 3, 4])
file.append(5) # Ajouter à droite — O(1)
file.appendleft(0) # Ajouter à gauche — O(1)
print(file)
file.pop() # Retirer à droite — O(1)
file.popleft() # Retirer à gauche — O(1)
print(file)
# Rotation
file = deque(range(5))
file.rotate(2) # Décaler à droite de 2
print(file)
file.rotate(-2) # Décaler à gauche de 2
print(file)
# Taille maximale (utile pour les files glissantes)
fenêtre = deque(maxlen=3)
for i in range(6):
fenêtre.append(i)
print(list(fenêtre))
deque([0, 1, 2, 3, 4, 5])
deque([1, 2, 3, 4])
deque([3, 4, 0, 1, 2])
deque([0, 1, 2, 3, 4])
[0]
[0, 1]
[0, 1, 2]
[1, 2, 3]
[2, 3, 4]
[3, 4, 5]
OrderedDict#
from collections import OrderedDict
# OrderedDict : garantit l'ordre même avant Python 3.7
# Son intérêt principal aujourd'hui : la méthode move_to_end
od = OrderedDict([("a", 1), ("b", 2), ("c", 3)])
od.move_to_end("a") # Déplace "a" à la fin
print(od)
od.move_to_end("c", last=False) # Déplace "c" au début
print(od)
OrderedDict({'b': 2, 'c': 3, 'a': 1})
OrderedDict({'c': 3, 'b': 2, 'a': 1})
ChainMap#
from collections import ChainMap
# ChainMap : vue unifiée de plusieurs dictionnaires
# Idéal pour gérer des configurations par niveaux
défauts = {"couleur": "bleu", "taille": "medium", "langue": "fr"}
config_utilisateur = {"couleur": "rouge", "taille": "large"}
config_session = {"langue": "en"}
# Priorité de gauche à droite
config = ChainMap(config_session, config_utilisateur, défauts)
print(config["couleur"]) # rouge (config_utilisateur)
print(config["langue"]) # en (config_session)
print(config["taille"]) # large (config_utilisateur)
rouge
en
large
array.array pour les données numériques homogènes#
import array
# array.array : tableau typé, plus compact qu'une liste de nombres
# Code de type : 'd' = double (float 64 bits), 'i' = int 32 bits
vecteur = array.array('d', [1.0, 2.5, 3.7, 4.2])
print(vecteur)
print(vecteur[0])
# Avantage : consomme beaucoup moins de mémoire qu'une liste
import sys
liste_int = list(range(10_000))
arr_int = array.array('l', range(10_000))
print(f"liste: {sys.getsizeof(liste_int)} octets")
print(f"array: {sys.getsizeof(arr_int)} octets")
array('d', [1.0, 2.5, 3.7, 4.2])
1.0
liste: 80056 octets
array: 80760 octets
Remarque 14
Pour les calculs numériques intensifs, ni les listes ni array.array ne sont la bonne réponse : NumPy offre des tableaux multidimensionnels avec des opérations vectorisées qui s’exécutent en code C compilé, plusieurs ordres de grandeur plus rapides. array.array reste utile lorsqu’on veut économiser de la mémoire avec des séquences numériques monodimensionnelles sans dépendre de NumPy.
Visualisation des complexités algorithmiques#
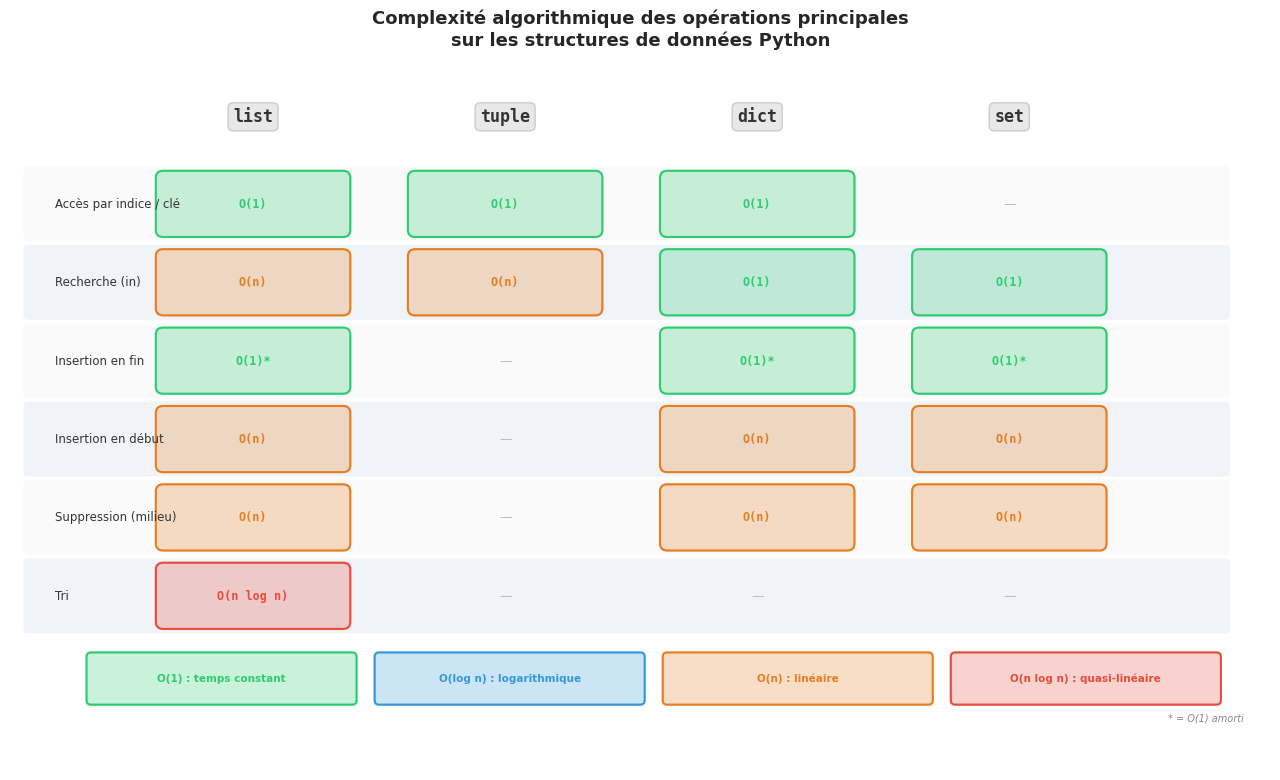
Résumé#
Dans ce chapitre, nous avons exploré les structures de données natives de Python et leur usage approprié :
Les listes (
list) sont des tableaux dynamiques ordonnés et mutables. Les opérations en fin de liste sont en O(1) amorti ; les opérations en début ou au milieu sont en O(n). Elles s’utilisent quand l’ordre importe et que les doublons sont autorisés.Les tuples (
tuple) sont des séquences immuables, hashables (si leurs éléments le sont), idéales pour les données structurées fixes. Le déballage (unpacking) et l’opérateur*restoffrent une syntaxe très expressive.collections.namedtupleajoute un accès par nom sans sacrifier l’immuabilité.Les dictionnaires (
dict) offrent un accès clé-valeur en O(1) et préservent l’ordre d’insertion depuis Python 3.7..get()évite lesKeyError;.items()permet d’itérer simultanément sur clés et valeurs.defaultdictetCountersont des spécialisations très utiles du modulecollections.Les ensembles (
set) garantissent l’unicité et le test d’appartenance en O(1). Ils supportent toutes les opérations ensemblistes classiques (|,&,-,^).frozensetest leur variante immuable et hashable.Le choix de la structure dépend de critères essentiels : la mutabilité, la nécessité d’un ordre, la tolérance aux doublons, la hashabilité et la complexité des opérations les plus fréquentes.
Le module
collectionsenrichit la bibliothèque standard avecdeque(insertions/suppressions O(1) aux deux extrémités),OrderedDict(avecmove_to_end), etChainMap(vue multicouche de dictionnaires).array.arrayest une alternative légère et compacte pour les tableaux numériques homogènes.
Dans le chapitre suivant, nous aborderons la programmation orientée objet en Python : classes, héritage, méthodes spéciales et les protocoles qui sous-tendent les structures de données que nous venons d’explorer.